


Turn-Taking Makes or Breaks Empathic Conversational Systems
Turn-taking, the subtle negotiation of who speaks when, forms the invisible architecture upon which meaningful interactions build themselves.

The dance of conversation follows intricate patterns that most humans navigate instinctively.
Yet, for machines designed to engage emotionally with humans, mastering these patterns represents one of the most significant challenges.
Turn-taking, the subtle negotiation of who speaks when, forms the invisible architecture upon which meaningful interactions build themselves.
The Multimodal Nature of Conversational Rhythm
The turn-taking we engage in during conversations has a more scientific basis than we tend to consider. This interaction transcends simple alternation. Instead, it operates through a complex orchestration of prosodic features (pitch variations, speech rate), visual cues (gaze direction, facial expressions), and linguistic markers.
Recent research by Zhi et al. (2024) demonstrates that prosody-aware turn-taking models dramatically outperform text-only approaches, with their ProTurn system showing a 23% improvement in prediction accuracy for emotional conversations.

Acoustic analysis showing turn-taking cues: voicing patterns and inbreath markers between conversational turns
Embodiment and Emotional Resonance
The physical presence of an agent fundamentally alters turn-taking dynamics. Ruijten and Haans (2023) demonstrate that embodied agents face distinct challenges in turn-taking compared to voice-only systems. Their research reveals that humans unconsciously expect embodied systems to utilize the full range of nonverbal cues, leading to heightened emotional disconnection when these expectations are not met.

Human-to-Robot often lack the multitude of verbal and vocal cues
Technical Challenges and Future Directions
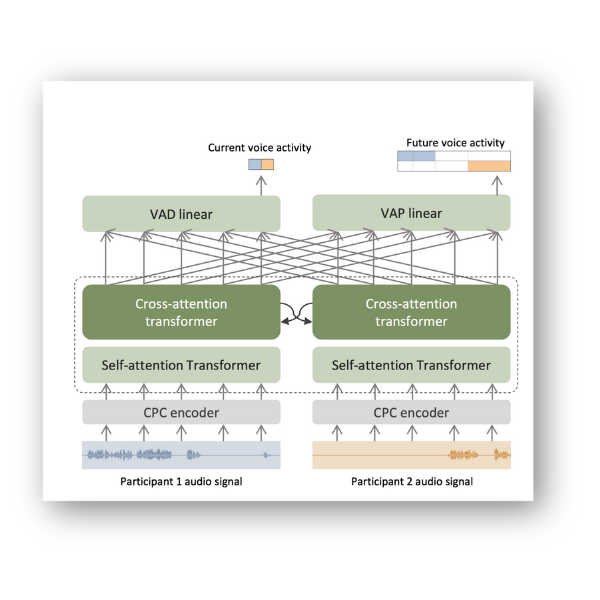
Architecture of the Voice Activity Projection (VAP) model showing parallel processing streams for conversation participants. The model processes raw audio from both speakers through CPC encoders and transformer layers to predict future speaking patterns, enabling more natural conversational turn-taking in AI systems.
The implementation of natural turn-taking faces significant technical barriers. Skantze et al. (2024) identify real-time processing latency as the primary obstacle, with even 300-millisecond delays creating noticeable disruption in conversational flow. Their proposed architecture integrates predictive processing to anticipate turn completion points before they occur.

The math behind turn-taking: Loss functions used in Voice Activity Projection models to quantify prediction accuracy for current (Lvad) and future (Lvap) voice activity patterns.
The Future of Conversational Rhythm

Comparison of turn-shift gap distributions across English, Mandarin, and Japanese conversations, showing cross-cultural patterns in turn-taking timing. Emphasizes the need for personalization.
As affective computing advances, turn-taking systems will likely evolve toward increasingly personalized models that adapt to individual interaction styles and emotional states. Language variation should also be included in these developments.
The integration of multimodal processing with emotional awareness promises conversational agents that not only know when to speak but understand the emotional significance of timing itself.
The quest for natural turn-taking represents more than a technical challenge. It embodies the essential rhythm of human connection. For machines to truly feel like intelligent emotional partners, they must master not just what to say, but the subtle art of when to say it.